Apache Spark is a “lightning-fast integrated analytics engine” for large-scale data processing. It can be taken in to use with cluster computing platforms like Mesos, Hadoop, Kubernetes, or as a separate cluster deployment. It can access data from a broad variety of sources comprising Hadoop Distributed File System (HDFS), Hive and Cassandra.

In this blog, we’ll discuss Spark, its libraries, and why it has become one of the most famous distributed processing frameworks in the industry.
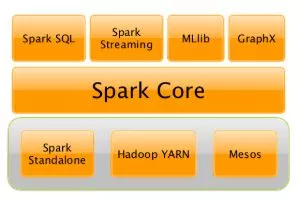
Spark Core
Spark is 100 times faster in memory and 10 times faster on disk than the customary Hadoop-MapReduce paradigm. How is Spark so swift? Spark Core is a distributed execution engine created from the ground up with Scala programming language. Scala is faster than Java and better at synchronized execution, a significant trait for developing distributed systems like a compute cluster.
Spark also gets a speed boost up from RDD (Resilient Distributed Dataset): an error-tolerant data structure that manages data as an absolute, distributed collection of objects. RDD does the logical divisioning of datasets, parallel processing, and in-memory caching simple, giving a more effective way to handle data in comparison to MapReduce’s sequential, map and reduce and disk-write heavy operations.
Spark SQL
Spark SQL allows you to process structured data through SQL and DataFrame API. A DataFrame arranges data into recognizable named columns similar to a relational database. It supports:
- Data formats like Avro, Cassandra, and CSV.
- Storage systems like Hive, HDFS, and MySQL.
- APIs for Scala, Java, Python, and R programming.
- Hive integration with syntax, HiveQL, Hive SerDes and UDFs.
An integrated cost-based optimizer, code generation and columnar storage make queries quick. Spark SQL takes full benefit of the Spark Core engine, allowing you to handle multi-hour queries and millions of nodes.
Spark Streaming
From social network analytics to video streaming, IoT devices, sensors and online transactions, the demand for tools that assist you process high-throughput, fault-tolerant, live data science bootcamp india streams is continually rising. The Spark Streaming module gives an API for receiving raw unstructured input data streams and processing them using Spark engine. Data can be ingested from various sources:
- HDFS/S3
- Flume
- ZeroMQ
- Kafka
- TCP sockets
- Kinesis
Industry examples of Spark Streaming are many. Spark Streaming has helped Uber manage the terabytes of event data streaming off of its mobile users to offer real-time telemetry for passengers and drivers.
MLlib
Turns out cluster computing and machine learning are a natural union, and Spark’s MLlib is a great way to make that occur. MLlib offers you a way to use machine learning algorithms like clustering, classification, and regression, with Spark’s fast and well-organized data processing engine.
GraphX
Spark uses graph theory to signify RDDs as vertices and operations as edges in a directed acyclic graph (DAG). GraphX enlarges this core feature with a complete API for directing graphs and collections, with support for common graph algorithms like SVD++, PageRank, and label propagation.
If you are also keen to learn Apache spark fundamentals then you should join an Apache Spark course through a reputed institution as they have right faculty and resources to explain the concepts to facilitate students’ learning.





